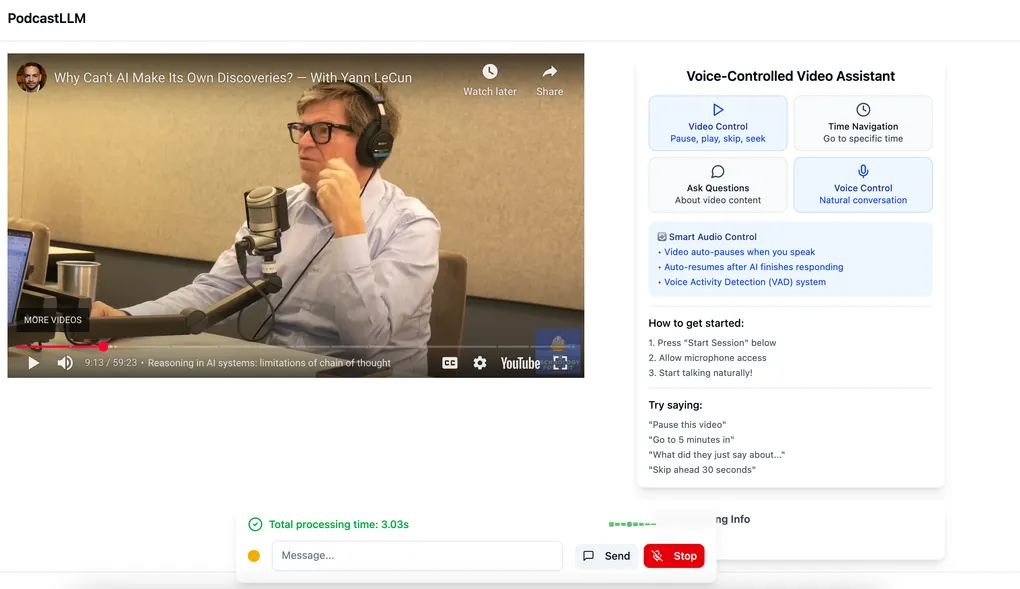
PodcastLLM
PodcastLLM is an application that allows you to interact with YouTube videos and podcast hosts in real-time using your voice, and receive answers with a cloned voice of the host. This project maintains a WebRTC connection between the client and backend to deliver AI-generated responses smoothly and in real-time.
Bringing Podcasts to Life: Building Real-Time Voice Interaction with YouTube Videos
This spring, I had the opportunity to work at the Horizon Lab at the University of Rochester. The goal was to build an interactive platform that would let users have natural voice conversations with video or audio podcast hosts, making passive video watching feel like an active podcast discussion.
Sometimes when watching podcasts, we want to ask follow-up questions or get clarification on specific points. What if you could actually talk to the host and get answers in their own voice?
In this project I tried many approaches to reach the current state. At first, I tried building just the frontend and using the OpenAI Realtime API completely as the backend, which gave me good low-latency answers and realistic conversations with AI. However, this didn’t give me enough flexibility to add custom logic in the middle of the process, and the API was really expensive for handling multiple users - it wasn’t scalable. So I decided to build our own backend and handle the WebRTC connection with the frontend, which I detailed in this blog post. While there is still a lot of work in progress to make the project vision a reality, I feel the base components are ready to reach that goal.
Architecture
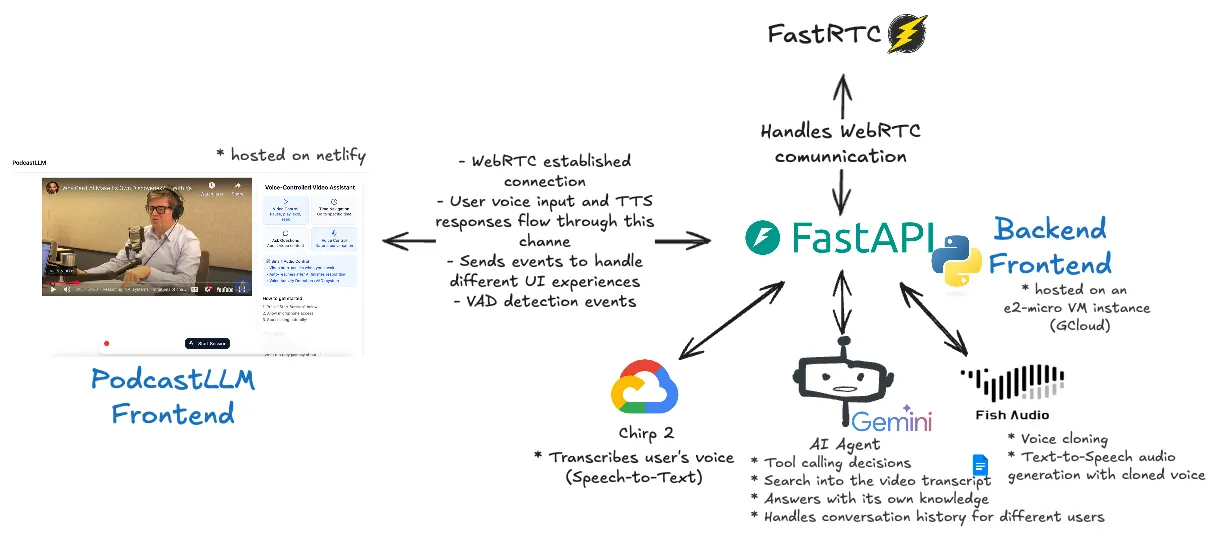
PodcastLLM works through a seamless voice interaction pipeline that I designed to feel as natural as having a real conversation with the podcast host.
First, the frontend establishes a WebRTC connection to send and receive audio streams directly to and from our FastAPI backend in real-time, providing the low-latency communication we need for smooth voice interactions. When the user speaks into their microphone, the frontend captures this and sends it to the backend. The backend incorporates a Voice Activity Detection (VAD) system, which handles when the user starts and stops speaking, so it knows when to continue processing and generate the answer. Kudos to the FastRTC team for making this library and saving me time and effort in handling WebRTC, and also for accepting my contributions with features that I needed for this project.
Once the backend’s VAD system detects when the user stops speaking, it sends the user’s audio to Chirp 2 from Google Cloud for speech-to-text (STT) transcription. The transcribed text then goes to Gemini AI. In this case, I chose Gemini 2.5 Flash since it supports a long context window (1M tokens) and fast token generation to not make the user wait too long for an answer. It also analyzes your question, decides what tools to use, searches through the video transcripts for relevant context, and generates a response that sounds like it’s coming from the actual host. For this, I had to tweak my prompt instructions many times, which still isn’t perfect.
Note: The AI agent can use many different tools depending on the type of question. For example, if the user wants a video summary, it simply summarizes the transcript. If the user’s question is about the current timestamp, we call a tool with that timestamp argument to search the transcript at that specific moment. If the user has a question about something not happening right now in the video, we search through the transcript without the timestamp argument, and so on.
For the voice generation part, I integrated Fish Audio’s text-to-speech service, which uses the cloned voice model that was created earlier from the host’s audio samples. This way, when Gemini’s text response gets converted back to speech, it sounds like the actual creator is talking to you.
The audio flows back through the same WebRTC connection to your browser, where it plays the response. Throughout this entire process, the backend sends real-time status updates to the frontend so you can see visual feedback - things like waveforms when you’re speaking, processing indicators, and other UI animations that let you know what’s happening behind the scenes.
Features

Voice-controlled podcast video tools demonstration
Background processing visualization after user query

AI response with cloned host voice
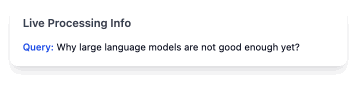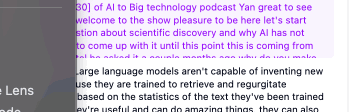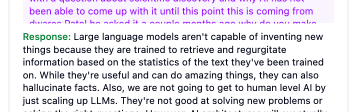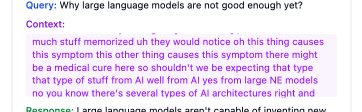
Context analysis and information retrieval for intelligent responses
You can interact with the video in two ways: with your voice after allowing the browser to use your microphone, or through an input box where you can write down your questions to be answered.
You can ask for video controls using natural language like:
- Please, rewind X seconds
- Go forward X minutes
- Go to minute 15 of the podcast
- Pause, stop, stop the video
- Resume, continue, etc.
On the other hand, you can ask questions to the host or about the video itself:
- What did you just say?
- What do you mean by …?
- Hey, can you clarify why you chose using Golang as a better option than Rust to rebuild the TypeScript compiler? (Something related with the video)
Voice cloning workflow:
- Checks if the host’s voice is already cloned
- If not available, automatically extracts audio samples from the video
- Processes the samples through a voice cloning API
- Uses the cloned voice model to generate natural responses
The application includes UI animations to enhance the user experience by showing real-time feedback: when the VAD (Voice Activity Detection) system captures their voice, what context the LLM is analyzing to generate responses, and what sources were used to answer the questions.
Next Steps
As I mentioned before, and if you try the demo, there is still a lot to improve for the quality of the app. The first critical issue I encountered is that the Chirp2 STT model is not fast enough to deliver a low latency experience. Additionally, it doesn’t include a way to insert context to better understand what you are saying - for example, technical words or names. I also tried a multimodal LLM model from Google, but the latency still remained high.
Second, there are many tweaks needed on the prompt engineering side to try different approaches that better fit getting the best answers and tool calling decisions.
Third, I need to separate the current AI Agent into multiple specialized agents, each handling specific scenarios. Currently, giving many tools to just one agent makes it easy for it to get confused about which tool to call. For now, it responds well to video control commands like pause, continue, or go to minute X. However, when answering questions and deciding whether to use the transcript or external knowledge, it struggles to choose the correct source.
I’d also like to try the Gemini Realtime Voice API to see if it fixes my low-latency experience problem, but I don’t want to lose my AI voice-cloned TTS feature.
Contact
If you have any suggestions or different experiences working with AI voice applications, let’s chat! My personal email is erikwasmosy98@gmail.com or LinkedIn.